
Overview
This project demonstrates a multimodal AI agent designed to read, understand, and reason over PDF files containing both text and images. The agent automatically extracts textual content and visual elements, embeds them into a shared vector space, and retrieves the most relevant context using a FAISS vector database.
Unlike traditional chatbots that rely only on text, this system enables image-aware question answering, making it suitable for documents such as technical manuals, scanned reports, invoices, research papers, and mixed-layout PDFs.
Key Capabilities
- Multimodal PDF ingestion (text + images)
- Unified embedding and semantic similar search with FAISS
- Context-aware retrieval for accurate answers
- Tool-based agent architecture for extensibility
- Real-time interaction via Gradio interface
Architecture & Workflow
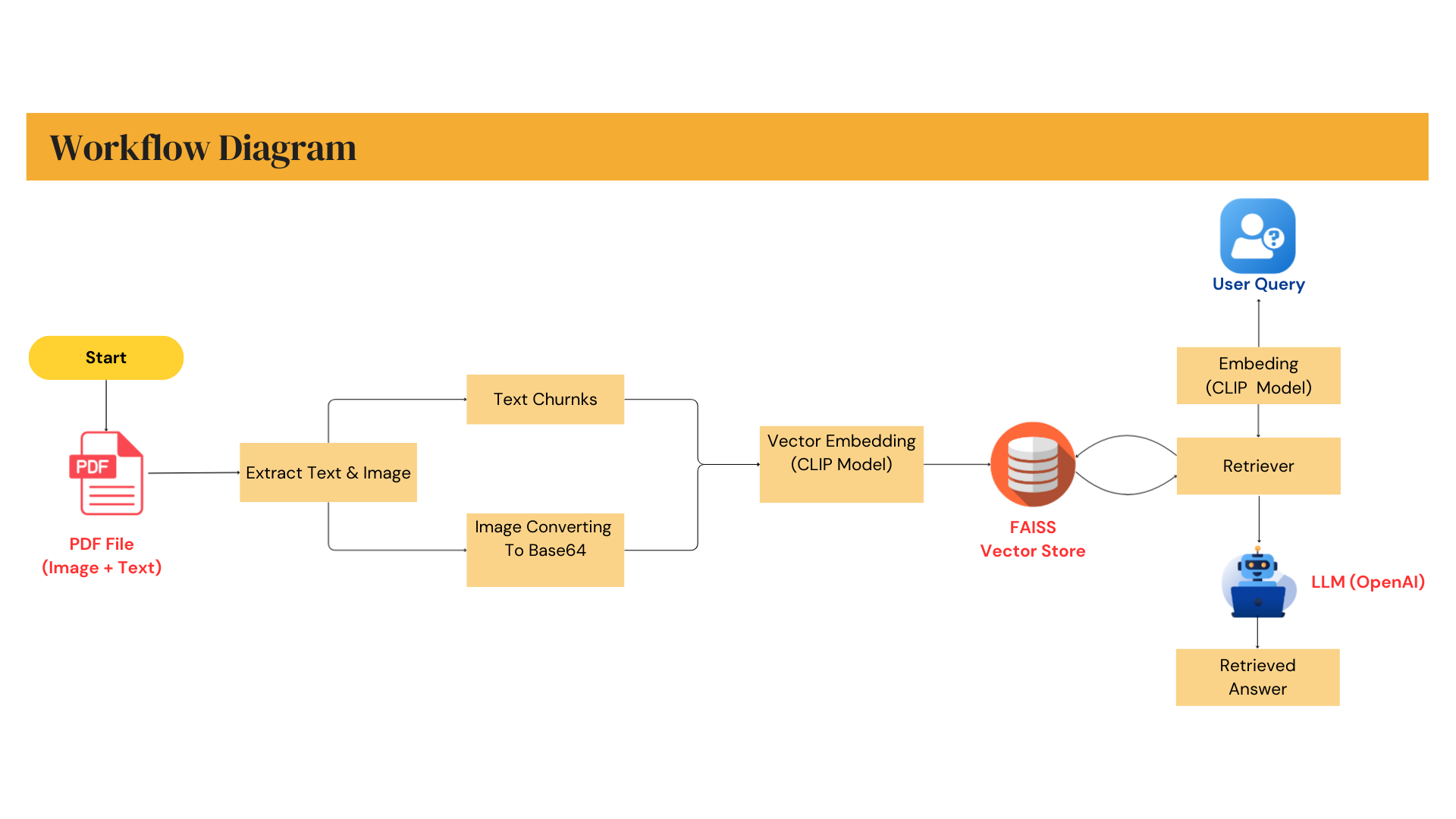
- PDF parsing and content extraction
- Image and text embedding using transformer-based models
- Vector storage and similarity search with FAISS
- Prompt orchestration and response generation via LLMs
This architecture allows easy scaling, model replacement, and deployment in real-world MLOps environments.
Technologies
- Python, Gradio
- LangChain
- OpenAI API
- FAISS Database
- Transformer Models
- Docker + MLOps